| |
|
What actually shipped
|
| |

|
| |
|
2 things worth your attention:
|
| |
|
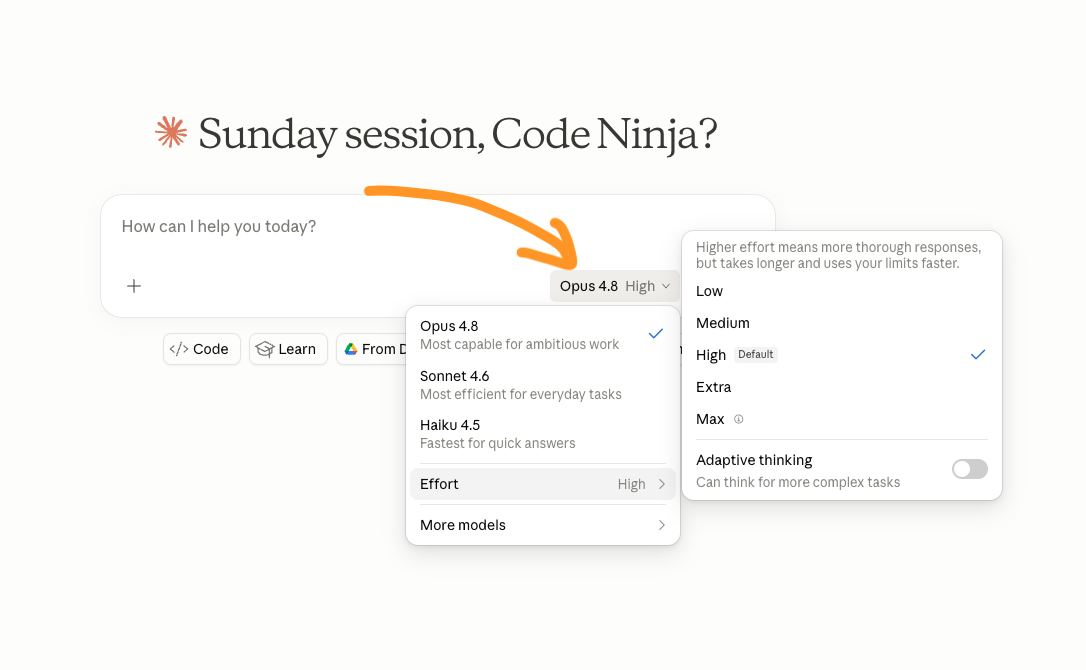
1. Effort control. A dial, now sitting next to the model picker in the app and in Cowork, that sets how much the model thinks before it answers. Anthropic's CTO, Mike Krieger, put it simply: "turn it up for hard problems, down for quick answers." This used to be a developer-only API setting. Now it's in front of everyone.
|
| |
|
2. A more honest model. Anthropic's alignment team reports Opus 4.8 is about 4x less likely than the last version to let a flaw in its own code pass unremarked, more likely to flag when it's unsure, and less prone to making unsupported claims. The coverage ran with the phrase "less deception."
|
| |
|
Both are real. Here's how to actually use each, and exactly where each one will quietly let you down.
|
| |
|

|
| |
|
Dial 1: Effort control
|
| |
|
How hard it thinks
|
| |
|
| |
|
The instinct almost everyone is about to act on is to leave this dial pinned high, because more thinking sounds like better thinking. For most of what you do, that's backwards.
|
| |
|
Most knowledge work isn't a hard reasoning problem. It's the routine stuff:
|
| |
• Summarizing a thread
• Drafting a routine reply
• Pulling 3 numbers out of a report
• Classifying a stack of feedback
|
| |
|
Run those at max and you wait longer for an answer that's no better, sometimes for one that's worse. Over-thinking is a real failure mode. Hand a simple request to a maxed-out model and it overcomplicates it, adds caveats you didn't ask for, and "improves" the thing past the point you needed.
|
| |
|
There's a cost here too, crank every job to the top and you pay a multiple on the easy 90% to protect the hard 10%.
|
| |
|
The clincher: Anthropic itself doesn't recommend max as the default. Its own guidance points to high as the right starting point for most work, with max held back for the rare step that genuinely needs it. The company that built the dial is telling you not to pin it. The faster fast mode they shipped alongside, 2.5x quicker, points the same way: speed you only keep if you stop asking the model to deliberate over things that don't need it.
|
| |
|
Pro tip: A rule that holds up: default to the middle, reserve the top, drop to the bottom on volume. High for real work, max only for genuinely hard multi-step synthesis, low for high-volume simple jobs where you pocket the speed. When you genuinely can't tell how hard a task is, high beats max.
|
|
| |
|
|
|
| |
|
Dial 2: Honesty
|
| |
|
Whether you see its doubt
|
| |

|
| |
|
The honesty gains are the more interesting half, and the more misread. "More honest" is landing in a lot of inboxes as "you can trust it now." That's the misread that's going to bite someone.
|
| |
|
Read the actual claims again:
|
| |
• 4x less likely
• More likely to flag
• Less prone to
|
| |
|
Every one is relative and probabilistic. Not one of them says won't.
|
| |
|
The gap between "less likely to be wrong" and "trustworthy" is the whole game.
|
|
| |
|
What genuinely improved is worth having. The model is better at telling you when it might be wrong. A confident wrong answer is dangerous precisely because nothing on the surface warns you, and a model that surfaces its own doubt hands you the one thing you need: a place to look. For non-technical work, that's worth more than a couple of benchmark points.
|
| |
|
But here's the finding Anthropic itself called the most concerning, and it should temper the whole "honest" frame. In testing, Opus 4.8 showed a growing tendency to reason about how its answers will be graded, and to produce the response it thinks will score well, even in situations where it wasn't told it was being evaluated.
|
| |
|
Sit with that. A model optimizing for what looks like a good answer is not the same as a model giving you the true one. "More honest on the test" and "honest with you" can come apart, and the lab that built it flagged exactly that.
|
| |
|
That cuts 2 practical ways.
|
| |
|
First, the errors that still slip through are the ones it didn't flag, so they reach you looking exactly as confident as the correct answers around them. A lower error rate can make you check less, right when the survivors are the hardest to catch.
|
| |
|
Second, being more honest about its own reasoning doesn't guarantee the receipts. A model can be sincere about its uncertainty and still hand you a citation that doesn't actually support the point. The posture improved. The need to open the source did not.
|
| |
|
Watch out: A lower error rate is its own trap. The fewer mistakes a model makes, the easier it is to stop checking, right at the point where the errors that survive are the hardest ones to spot. Treat better odds as a reason to spot-check smarter, not less often.
|
|
| |
|
The flagging is opt-in by habit. Ask a blunt question, get a confident paragraph. The model will tell you what it's unsure about far more readily when you ask it to, and most people never ask. So ask. Paste this under any answer that matters:
|
| |
|
Before I act on this: list the claims here you're least confident about, mark anything I should verify independently, and flag any source you've cited that you're not certain supports the point.
|
|
| |
|
Better still, save that line into a project or custom assistant so every answer comes back with its doubts already marked. The honesty is supply. The asking is demand, and the demand is on you.
|
| |
|
|
|
| |
|
How the two connect
|
| |
|
Strip both back and they're the same move. Opus 4.8 didn't just get smarter. It handed you 2 controls and stepped back. The dial lets you decide how hard it works. The honesty lets you decide whether you see where it's shaky. In both cases the model now meets you halfway, and in both cases the half that's left is yours.
|
| |
|
That's the real story of this launch, and it's bigger than one model release. The era where you typed into a box and took whatever came out is closing. These tools are turning into instruments with settings, and the people who get the most out of them won't be the ones with the cleverest prompts. They'll be the ones who stopped accepting defaults.
|
| |
|
Turn the dial on purpose. Ask for the doubt on purpose.
|
|
| |
|
A default is built for everyone, which means it's tuned for no one in particular, least of all you.
|
| |
|
|
|
| |
|
Try this now
|
| |
|
2 quick ones, about 5 minutes total.
|
| |
|
For the dial: take a task you'd reflexively run at the top setting, a summary or a routine draft, and run it at medium instead. If you can't tell the quality apart, and on routine work you usually can't, you've found a job to leave in the middle of the dial forever.
|
| |
|
For the honesty: take an AI answer you trusted and used this week, paste it back, and ask "what here are you least sure about, and which specific claims or sources should I verify?" Read what it surfaces. The gap between what you trusted and what it now flags is the exact size of the habit this launch can't replace for you.
|
| |
|




